From Workflow Automation to Agent Harnesses
What Changed and What's Next

I’ve said it before and been wrong, but what if 2026 actually is “the year of the AI agent?”
To test this hypothesis, I built an agent that handles end-to-end variance analysis.
If you’ve ever run FP&A or worked close to a controller, you know the drill. Pull the trial balance, scan for line items that moved more than they should have, dig into the general ledger to figure out why … then cross-reference what you know about staffing changes, vendor contracts, payer mix, and finally, write it all up for the CFO. Repeat next month. It takes hours (sometimes days) and the analytical structure is basically identical every single time. Only the numbers change.
Last year, as part of a close automation project, I built an automated workflow in n8n (a visual automation platform that lets you string together nodes, each one handling a discrete step). One node pulled the trial balance data. Another fed specific line items to an AI model with instructions on how to analyze them. Another formatted the output. And yet another routed it for review. The AI was one component in a larger pipeline, and the pipeline was entirely deterministic. Every decision branch, every output format, every conditional, every error-handling path was hard-coded by me in advance.
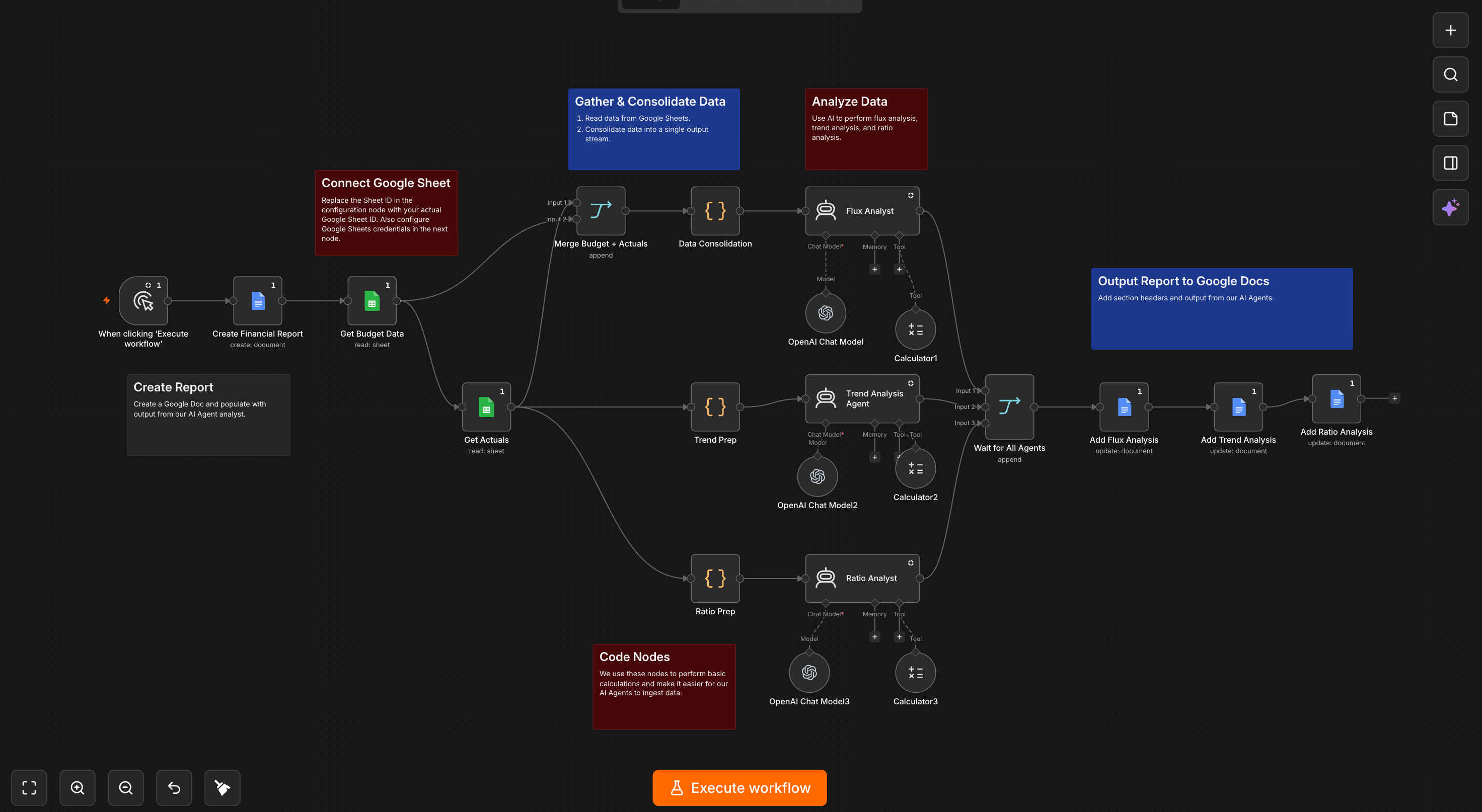
It worked. The output was consistent. The variance commentary it produced was useful (like actually useful. Not just technically-correct-but-useless). I was rather proud of it.
And … It also had a ceiling I hit almost immediately.
The Rigidity Problem
Every new scenario required a new branch. If a variance pattern showed up that I hadn’t anticipated, the workflow either handled it badly or didn’t handle it at all. The AI models inside the pipeline were powerful enough, but had no ability to reason about what they were seeing in context. They couldn’t connect two related variances across different accounts or say “I’m not confident about this attribution” because I hadn’t built a branch for uncertainty. The workflow executed the path I’d defined, and that was it.
For routine variance analysis on a stable chart of accounts, this was fine. For anything messier (anything where the interesting insight lives in the relationship between line items rather than in any single line item) the rigid pipeline broke down. I found myself building more and more branches to handle edge cases, which made the workflow harder to maintain and more fragile over time.
This is the fundamental limitation of workflow automation for analytical work. You’re encoding your own analytical judgment into a fixed decision tree. The AI contributes capability at individual nodes, but the intelligence of the overall process is yours, frozen in the workflow design at the moment you built it.
What Changed
Two things shifted over the past six-ish months that made a different approach possible.
First, language models got substantially better at multi-step reasoning, tool use, following complex instructions across long workflows, and maintaining coherence when the task required dozens of sequential decisions. The gap between “impressive in a demo” and “reliable enough for finance” closed meaningfully. Even smaller models like Claude Sonnet 4, which is what I ended up building on, can hold a seven-step analytical process in context, call tools in the right sequence, adapt its analysis to what it finds in the data, and maintain coherence across the entire run.
Second, the infrastructure around models matured. Tool-use protocols like Anthropic’s Model Context Protocol standardized how models interract with external systems. Human-in-the-loop patterns got formalized. State management, audit logging, approval gates, and checkpoint-and-resume became well-understood architectural components rather than things you had to invent from scratch.
The industry started calling this infrastructure the agent harness. The concept: instead of hard-coding every decision branch, you give the model structured access to data and tools, define the boundaries, set up verification and approval checkpoints, and let it reason through the workflow. The harness governs what it can do. The model figures out how to do it within those boundaries.
The Flux Agent
I rebuilt the variance analysis workflow as an agent harness. Same problem, but a fundamentally different architecture.
The Flux Agent follows a fixed seven-step process: scan the trial balance for accounts exceeding the materiality threshold, pull the journal entries behind each flagged account, load operational context (staffing changes, contract shifts, anything the numbers alone don’t show), identify root causes ranked by dollar impact with confidence levels, draft management commentary in the structure the CFO expects, stop for human review, and log the complete audit trail.
The model does the analytical reasoning. It decides which accounts to investigate, what the drivers are, how to frame the commentary. When it finds that salary savings from nursing vacancies and agency labor overspend are the same story showing up in two different line items, it connects them. When it can’t fully attribute a variance, it says so explicitly rather than speculating.
Agent harnesses are inherently non-visual … unless you’re one of those engineering nerds who likes to read lines of code; so I built a visual layer for this harness to show what it’s doing at each step. This is great for demo purposes, but probably not a bad addition for sharing with auditors as well!
But here’s what makes it a harness and why that word matters.
The agent can’t publish anything without human approval. The submit_for_review step architecturally blocks the pipeline. A human reviewer sees every section of the draft and must approve, edit, or reject each one before the agent can proceed. This is enforced in code. It’s how the system works, not a setting someone can toggle off.
The agent logs everything. Every piece of data it ingested, every GL entry it examined, every root cause it identified, every draft it produced, every decision the reviewer made. If internal audit asks how a number ended up in the board report, the answer is traceable from source data through analysis through human approval to final output.
And the agent’s tools are deterministic and separated from the reasoning. Seven tools, each a pure function reading from structured data files. The model provides the judgment. The tools provide the data. That separation means the data layer is testable independent of the model.
The Bigger Picture
The n8n build was reliable because it was rigid. The Flux Agent is reliable because the harness enforces verification, approvals, auditability, and data separation around flexible reasoning. Both approaches produce usable output, but the harness approach scales to the problems where you can’t anticipate every scenario in advance, which, if we’re being honest, is most of what finance teams actually deal with.
And this isn’t just my experience in a small lab. Morgan Stanley reports 98% advisor adoption of its AI tools in wealth management, with quality driven by evaluation suites and compliance QA built into the surrounding infrastructure. Robinhood pairs every FinCrimes investigating agent with a separate validation agent that checks the work before it can proceed. These are harness patterns. The model matters, the governance layer around the model is what got them to production.
Gartner predicts 40% of enterprise applications will include AI agents by end of this year. They also predict more than 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs and inadequate risk controls. The gap between those two numbers is a harness problem.
Sunday: The Implementation Guide
Sunday’s Pro edition goes deeper. What an agent harness actually is under the hood, the key components for finance, how to evaluate whether your team is ready to build one, and a downloadable deployment scorecard you can use to scope your first pilot. For the tech geeks here, I’ll also share a Google Colab project you can run yourself to see what’s going on under the hood.
Unlock the full implementation guide, component breakdown, python notebook, and deployment scorecard:
Building the harness is the hard part. If your team is exploring AI agents for finance workflows and you're not sure where to start, or you've started and you're not sure whether what you've built is production-ready, that's the work I do at RoboCFO.ai:
AI implementation strategy,
workflow automation,
data and analytics,
and governance design for finance teams.
We can help CFOs, controllers, and FP&A leads figure out which workflows are ready for agents, scope the controls infrastructure, and build systems that your auditors won't lose sleep over. Start with the AI Readiness Scorecard to see where your team stands, or get in touch if you want to talk about what a governed agent deployment looks like for your specific workflows.
